
Why AI Startups Are Hiring Filipino Teams for Data Labeling and Model Training
AI startups are increasingly hiring Filipino teams for data labeling and model training support. Here’s how these teams help prepare training datasets and improve AI model accuracy.
BUSINESS GROWTHREMOTE WORK INSPIRATIONENTREPRENEURSHIPTALENT ACQUISITIONSTARTUPS
YesHire Remote Team
3/5/20264 min read
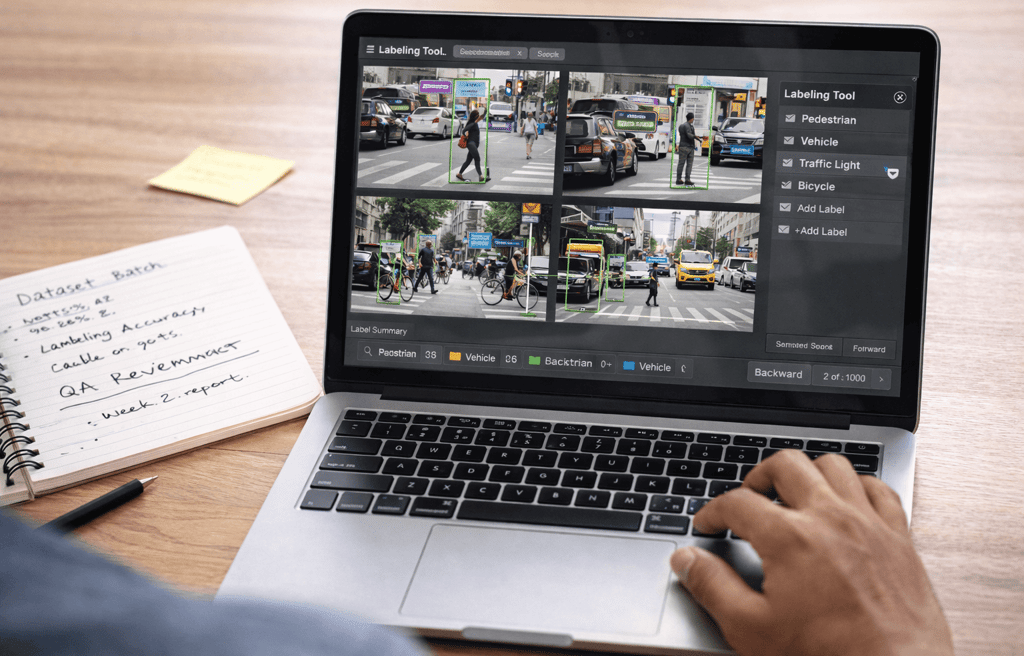
Artificial intelligence companies often focus their attention on algorithms, model architectures, and product features. Yet behind every successful AI system is something far less visible but equally important: the quality of the training data used to build it.
AI models do not learn in isolation. They rely on carefully prepared datasets that teach them how to recognize patterns, classify information, and make predictions. Preparing these datasets is a labor-intensive process that requires organization, accuracy, and consistency.
This is one reason many AI startups are increasingly turning to Filipino teams to support data labeling and model training workflows.
The Hidden Work Behind AI Systems
Before an AI model can produce useful results, it must be trained using large volumes of structured data. Images need to be labeled, audio files must be transcribed, documents require categorization, and training datasets need constant quality control.
This preparation work is known as data labeling or data annotation.
For example, if an AI company is developing computer vision software, thousands or even millions of images must be labeled with details such as objects, shapes, or behaviors. These labels allow the model to learn what each visual element represents.
The same principle applies to natural language processing models, recommendation systems, and many other AI applications.
Without properly labeled training data, even the most advanced models struggle to perform accurately.
Why Data Labeling Requires Human Expertise
Despite the rapid growth of automation tools, much of the training data preparation process still requires human judgment. Automated systems can assist with labeling tasks, but they often struggle with edge cases, ambiguous images, or complex scenarios.
Human reviewers help resolve these uncertainties.
They verify labels, correct errors, and ensure that datasets remain consistent across thousands of samples. This quality control step is critical because even small labeling mistakes can introduce bias or inaccuracies into an AI model.
For startups building AI products, maintaining dataset quality becomes a continuous responsibility.
This is where distributed operational teams become valuable.
The Growing Role of Filipino Data Operations Teams
The Philippines has become one of the most active global hubs for remote operational support roles, and AI data operations are quickly becoming part of that ecosystem.
image and video labeling
document classification
training dataset preparation
dataset quality assurance reviews
organizing training and validation datasets
These responsibilities require attention to detail and the ability to follow structured guidelines—two qualities that are particularly important when preparing training data at scale.
Many AI companies build small distributed teams dedicated entirely to these tasks so that engineering teams can remain focused on model development and experimentation.
Preparing Datasets for Model Training
Once labeling work is completed, datasets must be structured properly before they can be used for training models. This includes organizing the data into training, validation, and testing sets so that engineers can evaluate model performance accurately.
Data operations teams frequently assist with these steps by preparing files, verifying labels, and checking for inconsistencies.
If errors appear in the dataset, models may learn incorrect patterns or produce unreliable results. Maintaining high dataset quality helps prevent these issues before the training process even begins.
Because of this, many AI startups combine internal engineering teams with external data operations support.
Why Startups Look for Scalable Data Support
As AI startups grow, the amount of data required for model training expands rapidly. A small dataset used during early experimentation may grow into millions of data points once the product begins scaling.
Handling this volume internally can quickly overwhelm small engineering teams.
Distributed operational teams provide a way to scale labeling work without slowing down product development. Instead of engineers spending hours organizing training data, dedicated specialists manage the preparation pipeline.
Many AI companies also rely on structured data sources such as AI and ML companies database platforms to identify organizations operating within the artificial intelligence ecosystem and better understand how different companies are developing AI technologies.
These data sources help founders and product teams track the broader AI landscape while their operational teams focus on dataset preparation.
What This Means for AI Startups
AI development is often described as a technical discipline driven by algorithms and infrastructure. But the quality of the underlying data frequently determines whether those systems succeed or fail.
Well-prepared training data leads to stronger models, more accurate predictions, and more reliable AI products.
This is why many startups are investing earlier in structured data preparation and quality control processes.
Filipino data operations teams are becoming an important part of that effort. By supporting labeling workflows and training dataset preparation, they help AI startups build the operational foundation that strong machine learning systems depend on.
As the AI industry continues to expand, the demand for accurate, well-organized training data will only grow. The companies that manage this process effectively will often be the ones that develop the most reliable and scalable AI products.
Related Article:
Why Global Startups Are Turning to Filipino Remote Talent
The Secret Behind the Filipino Work Ethic: Why Clients Keep Coming Back.
7 Reasons Outsourcing to the Philippines Saves You More Than Money
The Future of Remote Work in Southeast Asia
Why 2026 Is the Year of Borderless Hiring
How AI Is Changing the Way Remote Teams Work
Why Small Businesses Are Adopting Remote-First Models
The 3 Mistakes Companies Make When Managing Remote Teams
What Western Managers Can Learn from Filipino Work Values
Inside YesHire Remote: How We Match Global Companies with Filipino Talent
The YesHire Advantage: Building Teams That Grow With You
Should We Thank AI Every Time It Helps Us?
The Hidden Cost of Ignoring Time Zone Overlaps
The Rise of the Global Filipino Professional
How to Onboard Remote Employees Like a Pro
Why SaaS Startups Are Hiring Filipino Teams for Sales Operations and Prospect Research
How Filipino Analysts Support FinTech Startups With Market Research and Competitive Intelligence
Connect
Streamline your hiring with pre-vetted talent.
Get hiring tips and updates — straight to your inbox.
support@yeshireremote.com
© 2025. All rights reserved.
YesHire Remote (Proudly Filipino!)
Rizal St. Old Albay
Legazpi City, Albay
Philippines 4500
We Offer Online Courses for Freelancers:
Learn More about YesHire Academy